|
Ваш репетитор, справочник и друг!
|

 Математическая статистика – краткий курс для начинающих
Математическая статистика – краткий курс для начинающих
2.2. Интервальный вариационный рядПредпосылкой построения интервального вариационного ряда (ИВР) является тот факт, что исследуемая величина В таких ситуациях затруднительно либо невозможно применить тот же подход, что для дискретного ряда. Это связано с тем, что ВСЕ варианты Поэтому здесь используется другой подход, а именно определяется интервал, Интервальный вариационный ряд (ИВР) статистической совокупности – это
упорядоченное множество смежных интервалов и соответствующие им частоты, в сумме равные
объёму совокупности. Дабы не плодить лишних букв и индексов, я никак не обозначил эти
интервалы. Придирчивый читатель, к слову, наверняка заметил, что через Следует отметить, что исследуемая характеристика не обязана быть непрерывной, и мы как раз начнём с такой задачи: Пример 6 По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в денежных
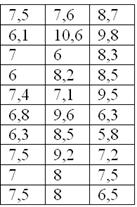
единицах): Решение: очевидно, что перед нами выборочная совокупность
объема Начнём с экстремальной ситуации, когда у вас под рукой нет Экселя или другого подходящего программного обеспечения. Только ручка, карандаш, тетрадь и калькулятор. Тактика действий похожа на работу с дискретным вариационным рядом. Сначала
окидываем взглядом предложенные числа и определяем примерный интервал, в который вписываются эти значения. «Навскидку» все
значения заключены в пределах от 5 до 11. Далее делим этот интервал на удобные подынтервалы, в данном случае
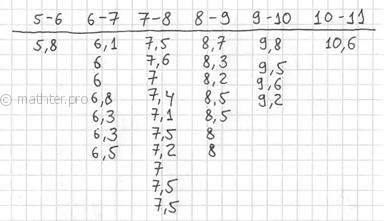
напрашиваются промежутки единичной длины. Записываем их на черновик: Теперь начинаем вычёркивать числа из исходного списка и записываем их в соответствующие колонки нашей импровизированной
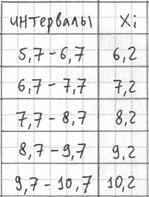
таблицы: Вычислим размах вариации: Теперь его нужно разбить на частичные интервалы. Сколько интервалов рассмотреть? По умолчанию на этот счёт существует формула Стерджеса:
* есть на любом более или менее приличном калькуляторе. В нашем случае получаем: Следует отметить, что правило Стерджеса носит рекомендательный, но не обязательный характер. Нередко в условии задачи прямо сказано, на какое количество интервалов следует проводить разбиение (на 4, 5, 6, 10 и т.д.), и тогда следует придерживаться именно этого указания. Длины частичных интервалов могут быть различны, но в большинстве случаев использует равноинтервальную
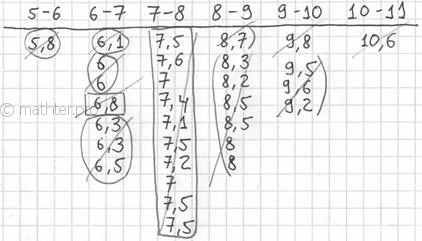
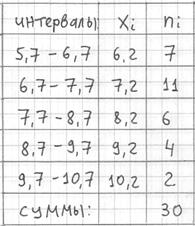
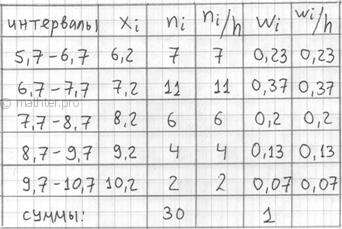
группировку: И коль скоро мы прибавили 0,04, то по пяти частичным интервалам получается «перебор»: Далее подсчитываем частоты по каждому интервалу. Для этого в черновой таблице обводим значения, попавшие в тот или
иной интервал, подсчитываем их количество и вычёркиваем: Так, значения из 1-го интервала я обвёл овалами (7 штук) и вычеркнул, значения из 2-го интервала – прямоугольниками (11
штук) и вычеркнул и так далее. Варианта В результате получаем интервальный вариационный ряд: при этом обязательно убеждаемся в том, что ничего не потеряно: …Да, кстати, все ли представили свой любимый товар, чтобы было интереснее разбирать это длинное решение? J Точно также как и в дискретном случае, интервальный вариационный ряд можно По каждому интервалу рассчитываем (не тушуемся): плотность частот
|
 2.2.1. Гистограммы
2.2.1. Гистограммы 2.1.2. Эмпирическая функция распределения
2.1.2. Эмпирическая функция распределения|
© mathprofi.ru - mathter.pro, 2010-2026, сделано в Блокноте. |