|
Ваш репетитор, справочник и друг!
|

 Математическая статистика – краткий курс для начинающих
Математическая статистика – краткий курс для начинающих
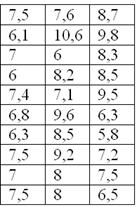
3.1.4. Как вычислить среднюю, моду и медиану интервального ряда?Начнём опять с ситуации, когда нам даны первичные статические данные: Пример 10 По результатам выборочного исследования цен на ботинки в магазинах города получены следующие данные (ден. ед.): Решение: чтобы найти среднюю по первичным данным, нужно
просуммировать все варианты и разделить полученный результат на объём совокупности: Эти подсчёты, кстати, займут не так много времени и при использовании оффлайн калькулятора. Но если есть Эксель, то,
конечно, забиваем в любую свободную ячейку: Что касается моды, то её оценка по исходным данным, становится непригодна. Хоть мы и видим среди чисел одинаковые, но среди них запросто может найтись так 5-6-7 вариант с одинаковой максимальной частотой, например, частотой 2. Поэтому модальное значение рассчитывается по сформированному интервальному ряду (см. ниже). Чего не скажешь о медиане: забиваем в Эксель =МЕДИАНА(, выделяем мышью все числа, закрываем
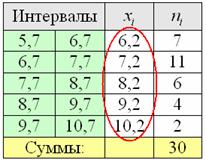
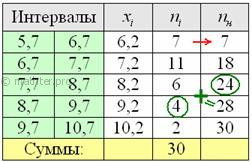
скобку ) и жмём Enter: Но в Примере 6 я проводил сортировку совокупности по возрастанию (вспоминаем и сортируем), и это хорошая возможность повторить формальный алгоритм отыскания медианы. Делим объём выборки пополам: Ситуация вторая. Когда даны не первичные данные, а готовый интервальный ряд (что в учебных задачах бывает чаще). Продолжаем анализировать этот же пример с ботинками, где по исходным данным был составлен ИВР. Для вычисления средней потребуются середины Здесь мы использовали упомянутый ранее приём – приблизили интервальный ряд дискретным, и это приближение оказалось весьма эффективным. Впрочем, с современными программами не составляет особого труда вычислить точное значение даже по очень большому массиву первичных данных. Если они нам известны ;) С другими центральными показателями всё занятнее. Чтобы найти моду, нужно найти модальный интервал (с максимальной частотой) – в нашей задаче
это интервал
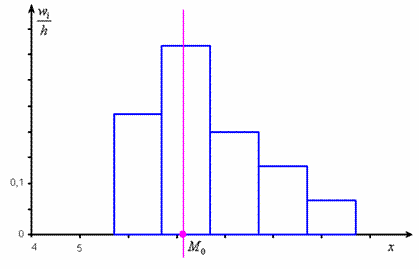
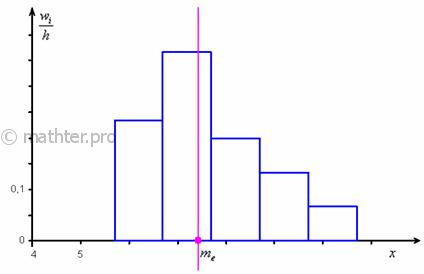
Таким образом: Не вдаваясь в геометрию формулы, просто приведу гистограмму относительных частот
и отмечу Справочно остановлюсь на редких случаях: Вот такой вот депеш мод :) И медиана. Она рассчитывается чуть по менее страшной формуле. Для её применения нужно найти медианный интервал – это интервал, содержащий варианту (либо 2 варианты), которая делит вариационный ряд на две равные части. Выше я рассказал, как определить медиану, ориентируясь на относительные накопленные частоты
Формула медианы:
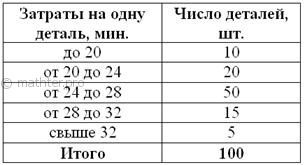
Таким образом: Ответ: По сравнению с предыдущей задачей Задание для тренировки: Пример 11 Для изучения затрат времени на изготовление одной детали рабочими завода проведена выборка, в результате которой получено
следующее статистическое распределение: Решаем эту задачу в Экселе – все числа и инструкции уже там. Если нет Экселя, считаем на калькуляторе, что в данном случае может оказаться даже удобнее. Образец решения, как обычно, в конце книги. Это, кстати, уже каноничная «интервальная» задача, в которой исследуется непрерывная величина – время. Что ещё можно сказать по теме? Несмотря на разнообразия рассмотренных показателей, их всё равно бывает не достаточно. Существуют крайне неоднородные совокупности, у которых варианты «кучкуются» во многих местах, и по этой причине средняя, мода и медиана плохо характеризуют положение дел. В таких случаях вариационный ряд дробят с помощью квартилей, децилей, а в упоротых специализированных исследованиях – и с помощью перцентилей. Квартили упорядоченного вариационного ряда – это варианты В тяжёлых случаях проводится разбиение на 10 частей – децилями И в очень тяжелых случаях в ход пускается 99 перцентилей После разбиения вариационного ряда каждый участок исследуется по отдельности – рассчитываются локальные средние и другие показатели. В учебном курсе квартили, децили, перцентили встречаются редко, и посему я оставляю этот материал (их нахождение) для самостоятельного изучения. Ну а сейчас мы переходим к изучению второй группы статистических показателей: |
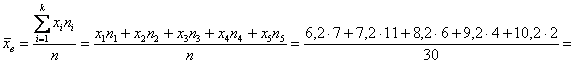
 3.2. Показатели вариации
3.2. Показатели вариации 3.1.3. Медиана
3.1.3. Медиана |
© mathprofi.ru - mathter.pro, 2010-2026, сделано в Блокноте. |